The volume of activity taking place in engineering teams can be mind-boggling, making engineering teams rather difficult to manage. Successful engineering managers, however, are adept at steering their teams to success by tactfully monitoring and using software metrics.
Software metrics enable visibility and acquiring a complete understanding of the software delivery process from concept to production can help in the discovery of bottlenecks or process concerns that, when solved or optimized, can enhance the engineering team's health and efficiency.
Code Churn is one such metric that managers use to analyze their team's progress. Monitoring code churn patterns across the development lifecycle can enable managers to identify when an engineer is stuck or struggling, or when there are concerns with external stakeholders, or if an approaching deadline might be at risk.
What is code churn?
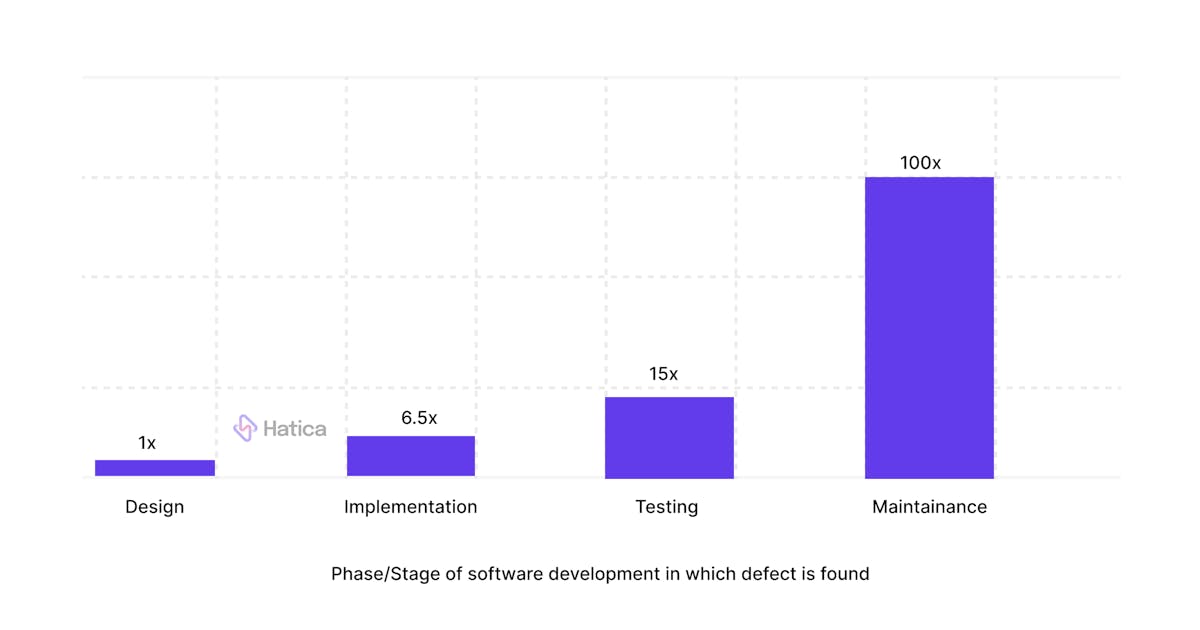
Code churn, also known as code rework, is when a developer deletes or rewrites their own code, shortly after it has been composed. Code churn can be good or bad depending upon when and why it is taking place. For example, consider a scenario wherein a large portion of your team's code churn occurs close to delivery. This might be due to any number of factors, perhaps outside of your team’s control. When managers have access to view only the metric without context, it becomes difficult to judge the nature, cause, and consequences of the problem. Thus, code churn is worth delving into in-depth since identifying a mistake during the design process is significantly less expensive than catching it during maintenance. Here are some common causes of code churn and some possible countermeasures:
Causes of Code Churn
In many scenarios, code churn is unavoidable. Redesigns, prototypes, and proof-of-concepts are all examples of situations when huge sections of code are expected to be rewritten and these levels will differ depending on the developer, the sort of project they are working on, and where the team is at in the software development lifecycle. So, if you find exceptionally high churn, assess if it's normal or whether something is amiss.
High levels of code churn usually reveal critical issues outside of the conventional development process; it might be that the team's product owner is supplying unclear specifications, or the developer is facing difficulties. Addressing these issues will assist to reduce friction in the development process, allowing the team to spend less time waiting on others or dealing with confusing specs and more time concentrating on the main challenges at hand.
Some of the most prevalent workflows and dynamics that can lead to exceptionally high amounts of code churn are:
- Prototyping and complex tasks
- Ambiguous project and task requirements
- Questing for perfect code
- Burnout and retention/turnover issues
Prototyping, R&D, and Exploratory Churn
It is common across development cycles that a newly composed piece of code often goes through multiple changes. The volume of code changed and how often the code is changed in a short period of time can vary due to several factors.
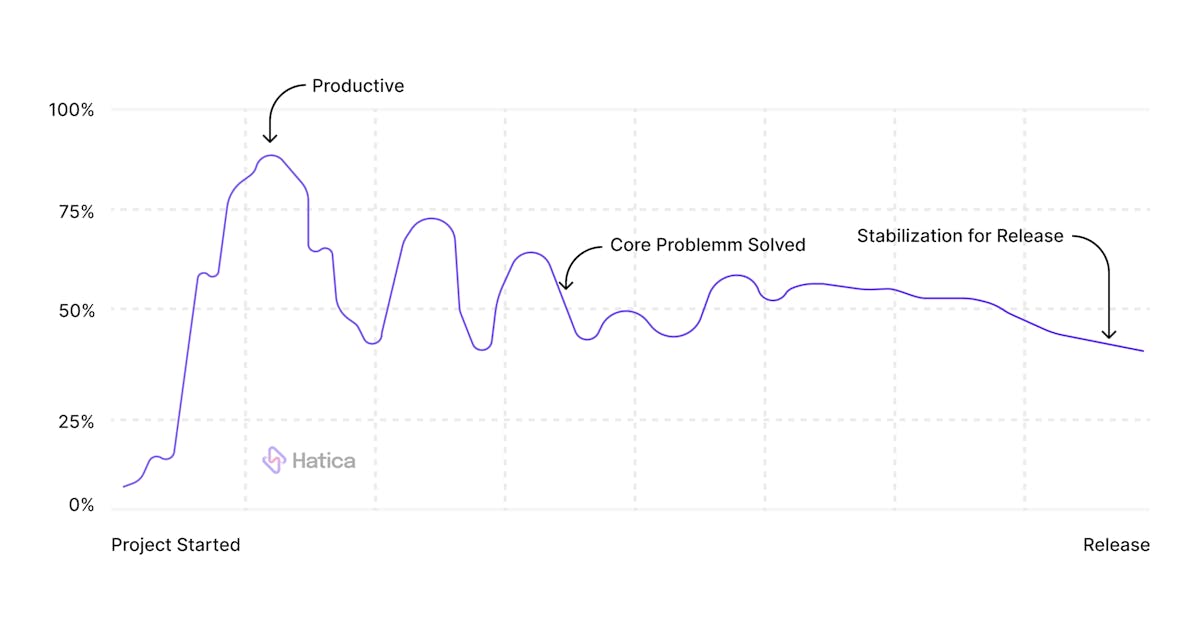
When a developer gets immersed in exploratory projects, he or she may make compromises in code standards in order to achieve a faster proof of concept, only to refine it later after an ideal solution has been found. Although there is more code churn in the short term, the approach is productive as it helps the developer to rapidly explore new ideas, thus proving beneficial. Redesigns, prototypes, and proof-of-concepts are all instances when huge sections of code are likely to be rewritten.
Prototyping is a natural and healthy trend, therefore expect things to be headed in the right direction as long as code churn decreases down the development lifetime. It's OK to allow developers the time and space to research and develop at this stage.
However, if the pattern continues for an exceptionally long period of time, beyond what is expected to occur for the current task, it might indicate that the developer failed to completely comprehend specific components or the entire problem, or the problem might be more complex than expected. To recognise such a situation, become familiar with the developer's normal level of code churn and keep a watch out for developers’ churn patterns.
Counter measures:
A developed set of principles and work processes improves any software development team:
- Make sure the amount of time developers spend prototyping is reasonable for the level of business risk and the value you expect from the product.
- Set up a pair programming session with a more senior engineer if the problem proves to be more difficult than planned, or if a developer is working on a new set or domain of challenges.
- Ensure that developers do not create custom solutions for problems that can be handled by existing resources unless the project requirements specify otherwise
Scope Creep
Scope creep is a pattern in which the scope of a project grows or changes after it has been implemented. Scope creep is often, but not always, gradual and hence undetectable. Adding features in the middle of a project necessitates a significant amount of unanticipated labour.
Out-of-scope tasks can occur even in the most well-defined projects. As a manager, you must keep an eye out for runaway scenarios in which engineers are expected to bear an unjustified rise in scope.
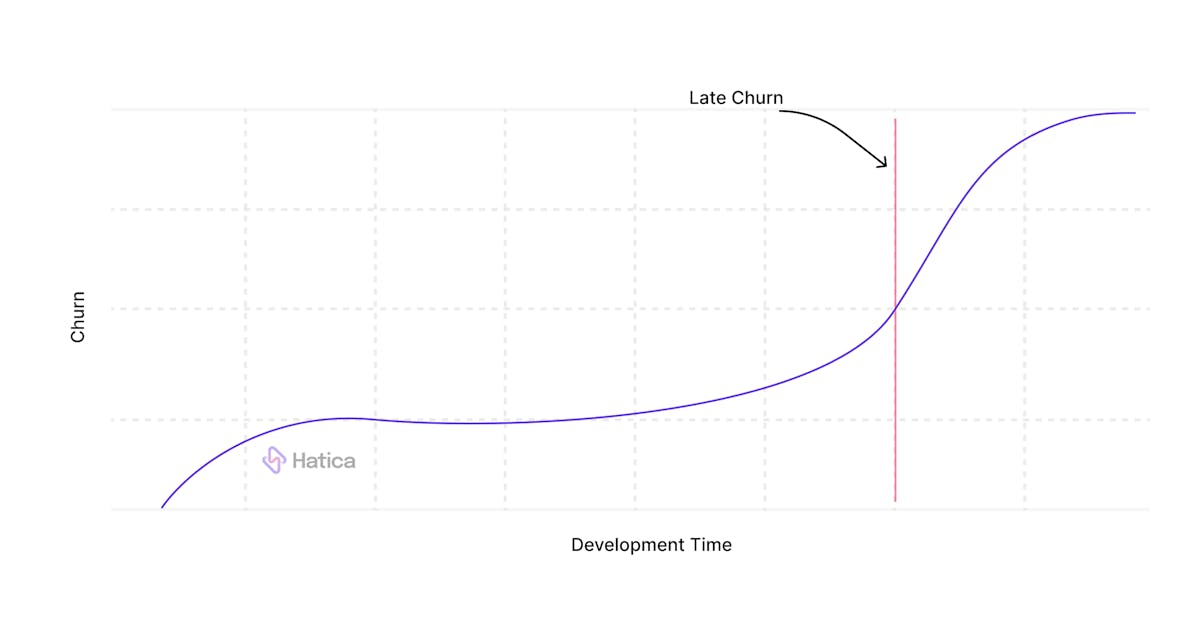
As features are completed, the challenge that a team is attempting to solve should become smaller. Often, an indicator of scope creep is characterized by a sudden increase in churn levels at the end of a development life cycle that isn't always caused by a code review, thus indicating the fact that maybe some new features or requirements have arrived during the later stages of the project.
Counter measures:
Requests for modifications can happen at any time, but many of them can be avoided.
- Examine and optimize the requirements gathering process from external stakeholders. This will avoid scope creep becoming a pattern across sprints.
- Scope creep is caused by a lack of preparation and attention throughout the design process. It is not the engineer's obligation to take on the effort that results from incorrect specifications. Hence it is important that you make it clear to those in charge of pushing a poorly planned project through that it is not acceptable.
- Before beginning development, share any relevant discoveries with your customer and their specialists to determine whether, how, and when to include extra requirements.
- Perform a brief search to check if there's anything in the news that might affect the project (new technology, legislation, critical technology partners going out of business, etc.).
Ambiguous Software Requirements
Defining specific software requirements is the beginning of a software development process and the guarantee of its consistency in later stages. During this phase the Software Requirements Specification (SRS) document should clearly lay down the foundations and guidelines that the parties involved in the project should follow.
Inconsistencies and ambiguities in the SRS document spread to subsequent phases of software development, compromising the quality of the final product. When a Product Owner gives partial or incomplete requirements, additional engineering effort is spent filling in the gaps, or the developer is forced to work with unclear specifications or to decode using their best reasonable estimate. Some of those assumptions will undoubtedly be erroneous, resulting in increased churn.
The amount of tolerance for ambiguity in requirements varies depending on the experience of the engineers implementing the project. In comparison to an established team of developers, a team that comprises mostly fresh members will ultimately demand tighter direction.
Another common occurrence under this subject matter is when the Product Owner makes revisions to their demands after the implementation has begun which eventually leads to missed deadlines. The same product owner's reoccurring scope creep tends to indicate this pattern. On the back of the sprint, you can observe a substantial increase in code churn that wasn't driven by code review.
Counter measures:
Code churn caused by ambiguity is problematic, although it may be avoided by:
- In most cases, the Product Owner's manager should be in charge of managing the problem, they could just provide instructions on any areas the individual tends to neglect when writing and creating specs.
- Check with your developers to see whether they believe the objectives are well-defined. Maybe conducting standup meetings to verify the same.
Questing for perfect code
Oftentimes, after resolving the issues brought up during the review process, the developer begins giving their code the last polish, and in the process, new faults surface, creating delays. This pattern is defined by heavy churn in the mid-late phases of a sprint or project after the work is ready for production.
With a few developers, this is a rather constant pattern. It's simple to see in their code churn history, and it might also be reflected in a pattern of work delays. The major reason is when an engineer's definition of "good enough" differs from the company's, or when an engineer makes enhancements that are well above what is required from a commercial standpoint without providing significant value.
If there is a lot of churn leading up to a release, the release may be impacted. Excessive reworking of code shortly before a deadline might indicate that the release should be postponed.
Counter measures:
For some engineers, perfectionism is a difficult practice to overcome, and they must be progressively trained away from it. Here are a few techniques to keep things under control:
- By establishing a shared understanding of what constitutes "good" code
- By asking a more senior engineer to assess the same code in the context of the project.
- By analyzing whether the work that was originally presented met team standards, and if the new work is a consequence of feedback from the review process that resulted in a significant improvement to the original code.
Burnout and turnover
Burnout or engineer dissatisfaction could be indicated by a high level of churn combined with indicators from several performance metrics such as responsiveness, active hours, code efficiency, and low throughput of your developer over an extended period of time.
This may arise as a result of a work pattern known as "Bit Twiddling," in which an engineer devotes his or her whole attention to a particular section of the codebase for an extended period of time, making only minor modifications here and there. It's like putting together a jigsaw puzzle and realizing you're not making any progress — and it typically happens because the engineer doesn't completely comprehend the problem or the context in which the modification is being made.
Counter measures:
On the job, software developers are at danger of burnout. Everyone handles stress differently, but the long-term effects might include developers becoming disinterested, failing to show up for work, considering job changes, and, well, it can get worse.
When discovered early enough, burnout may be swiftly reversed, therefore practice the following to keep all of your developers intact:
- Provide regular feedback to developers and show appreciation for their efforts.
- Unwanted work should be outsourced or rotated so that no one is trapped with a task they despise.
- Assign new tickets and projects which would help enable the developer to explore new and interesting areas of the codebases.
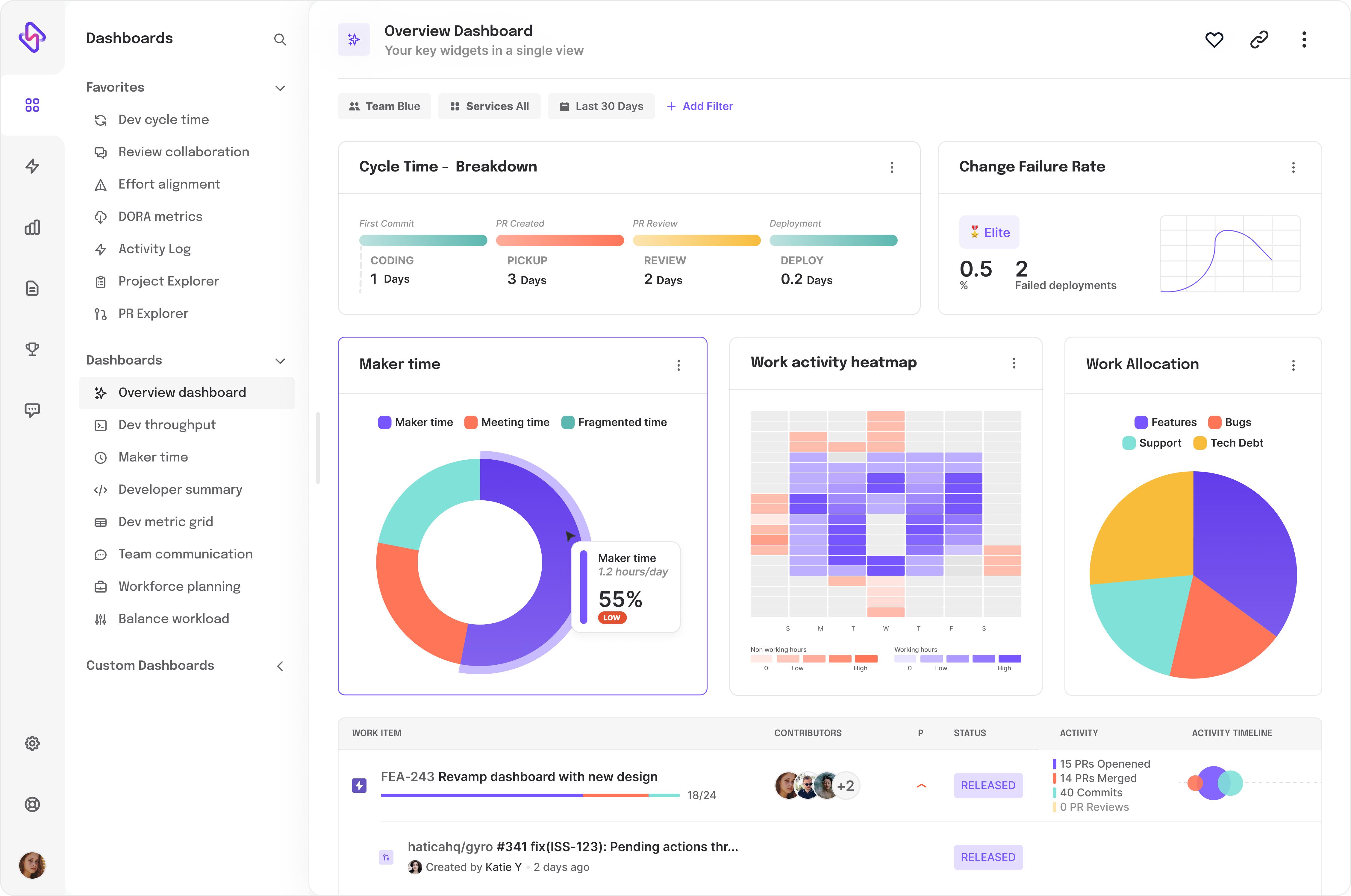
Track Your Software Metrics
💡 One of the primary reasons engineering teams have not been able to leverage essential software development metrics like code churn is because measuring these metrics has been complex and expensive. But now, Hatica’s engineering analytics platform makes it quick and simple to track this metric for your teams. Just connect your Github, Gitlab or any other code hosting platform you use and let Hatica deliver code churn dashboards in minutes. Request a demo here to know more about Hatica and how it equips engineering leaders and teams with data-driven insights into their engineering development process.