💡Invest in infrastructure to facilitate faster and more stable builds. Modern testing tools such as the test-at-scale product by Lambdatest are equipped with the intelligence to run only the impacted tests and not the whole test suite, thereby greatly reducing a developer’s waiting time.
3. High Rework Time
Rework time is the time taken for a developer to delete or rewrite their code shortly after it has been composed, after a PR review. When it comes to rework time, high is not necessarily bad because when PRs receive high-quality code reviews, they inevitably lead to higher rework. However, when rework time is too high for your team’s benchmarks, it can be an indicator of issues. So what should managers do?
Solution for High Rework Time
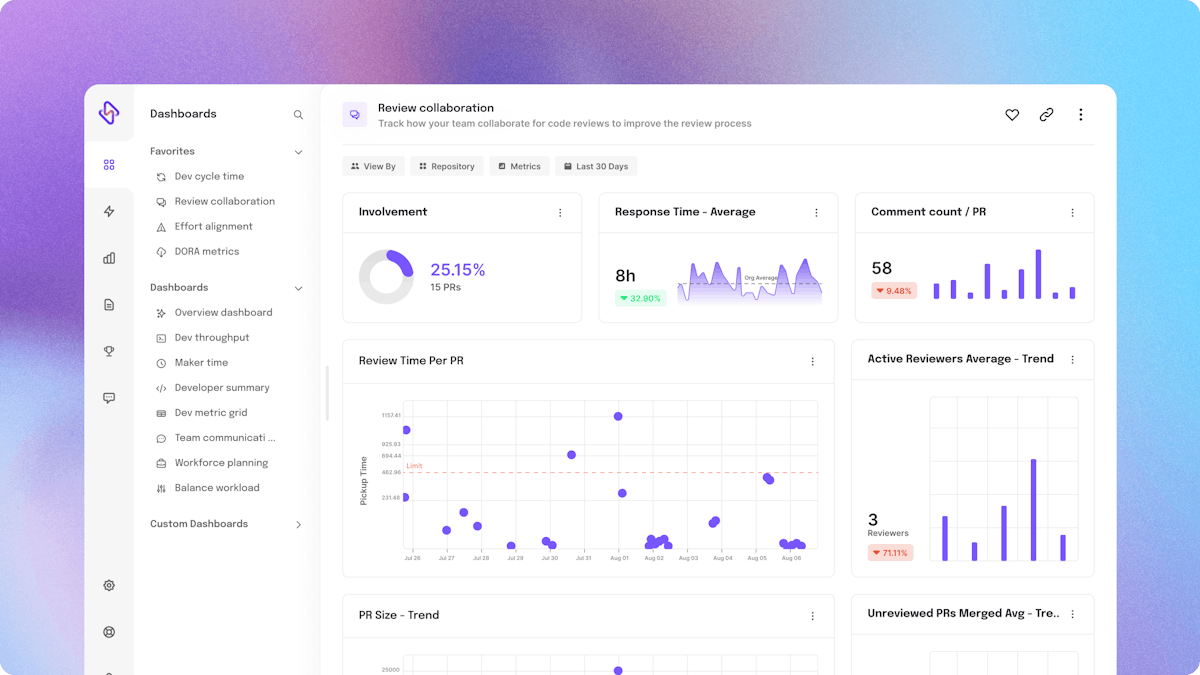
- Look at the response time of reviews which measures the average time it takes for your reviewers and authors to respond to comments. Your pickup time (first review) might be quick but its often that the authors and the reviewers take long to respond to review comments thus increasing the time it takes to get the code approved.
- Look at the rejection rate of your PRs - how often are PRs not approved in the first review? On the flipside when you have a 100% approval rate, it can also be an issue, especially in large teams, since it can be an indicator of low-quality reviews.
- Note if your teams’ tasks are well-specced and monitor to see if rejection rate is high. These can happen often due to tasks being poorly defined without adequate input from the project teams, leading to developers having to make changes to accommodate a different requirement.
- Integrate automatic checks like static code analysis and linting so that reviewers don't need to spend time on nit pics that could be easily caught by machines.
4. Time to Deployment
Deploy time is the time between when a PR is approved and when it is deployed. Obviously, teams generally prefer low deployment time. This metric corresponds to DORA metrics that can be used to identify opportunities for process improvement. This metric is critical since productivity is all about deployed code - if a code is not deployed then effectively, the output is nil for that effort.
It’s important to note that time to deploy cannot be measured using fixed thresholds since the value would differ based on the kind of service/project under question. For instance, mobile apps will have releases further apart than a micro service which might have more frequent releases. Hence it’s important to identify the right benchmarks for each deployment.
Generally, the time to deploy is higher than the benchmark if there is a long wait time or flaky builds in CI/CD that delay merges. At other times, when a PR needs multiple or slow tests before deployment, it can lead to increased time to deploy.
Deployment frequency (DORA metric) is the frequency with which a team pushes changes to production. Managers can ensure better productivity by structuring team workflows to allow them to ship smaller, more frequent deployments, thereby optimizing time to deployment, lowering risks, and providing better customer benefits.
How Does the Cycle Time Metric Help Dev Managers?
The primary purpose of the cycle time metric is to help dev teams identify blockers in the team workflow in order to help them speed up their delivery. As a lagging indicator, i.e., a metric that confirms patterns that are in progress, the cycle time metric can be used as a signal of underlying issues in an engineering team’s workflow. Thus, along with related metrics, it can be used to do a root cause analysis as to why the team faces process issues. (Read on for more details)
High cycle time has wide-ranging consequences and manifests across the project management lifecycle. For instance, healthy or optimum cycle time has a tremendous impact on the productivity of the project management lifecycle.
Stale PRs and branches
High cycle time caused by high time to review and rework can lead to authors and reviewers losing context to their work. This can result in stale tasks and production issues. Stale PRs also hurt productivity and workflows since they often result in huge merge conflicts that are difficult to resolve. Oftentimes, the merge conflicts are a result of multiple other code changes and when the code merge isn’t done well, this can lead to bugs in the product. Hence, when managers are able to preserve a healthy cycle time, they can prevent stale PRs and branches and protect the quality of their team’s work and productivity.
Developer Experience
When authors have to wait too long to get code reviews or when they don’t get quality reviews or get a constant rejection from reviewers, cycle time spikes, severely hurting the developer experience.
Workload Balance
High cycle time manifests as teams not meeting their promised goals in sprints - say you run weekly sprints, if your cycle time average is not less than 4 days, you will most likely end up with a large number of spillover tasks since all tasks would get closed towards the end of the sprint while the rest will spillover. Spillover tasks cause a cascading effect on individual and team productivity and ability to deliver. Keeping healthy cycle time automatically leads to better workload balance in multiple ways; It encourages more people involved in code reviews to keep the pickup time low, and managers are enabled to assign tasks better in their sprints to keep spillover of tasks to a minimum.
Healthy Thresholds for Efficient Workflows
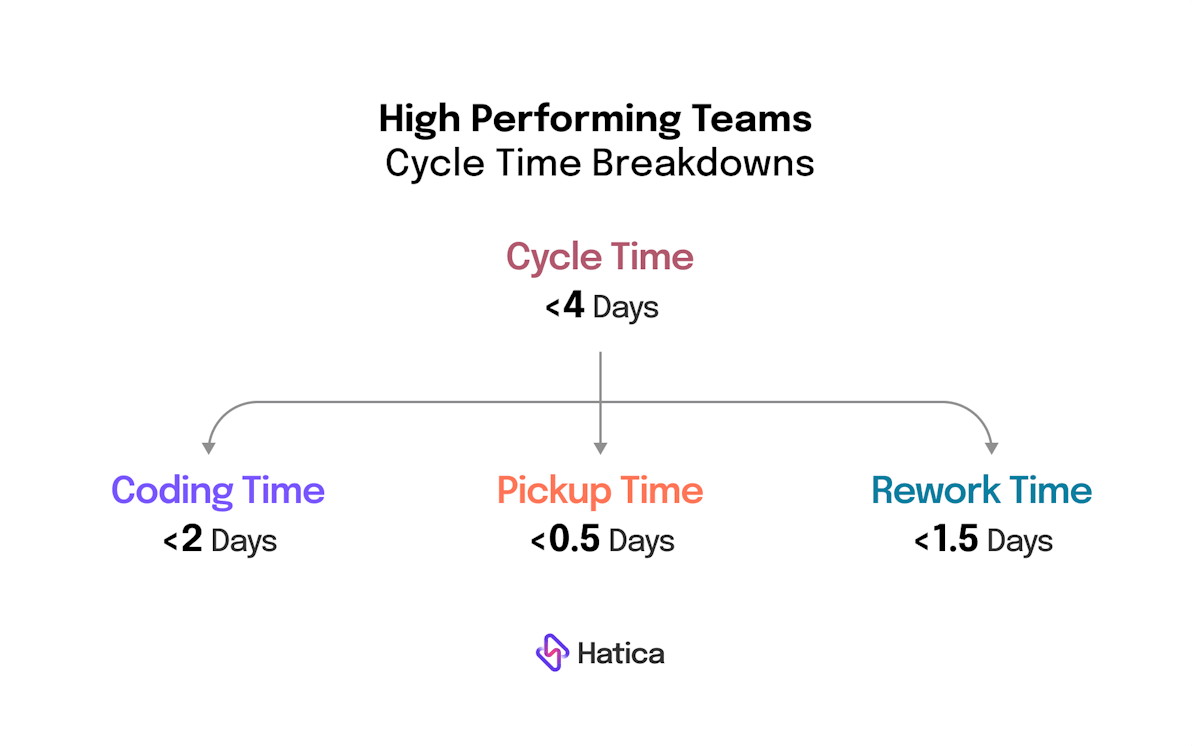
Although thresholds depend on workflows and the nature of the projects, whether mobile or a microservice, and/or the repo, the overall cycle time including optimum target times for coding to merge time are generally similar across project types.
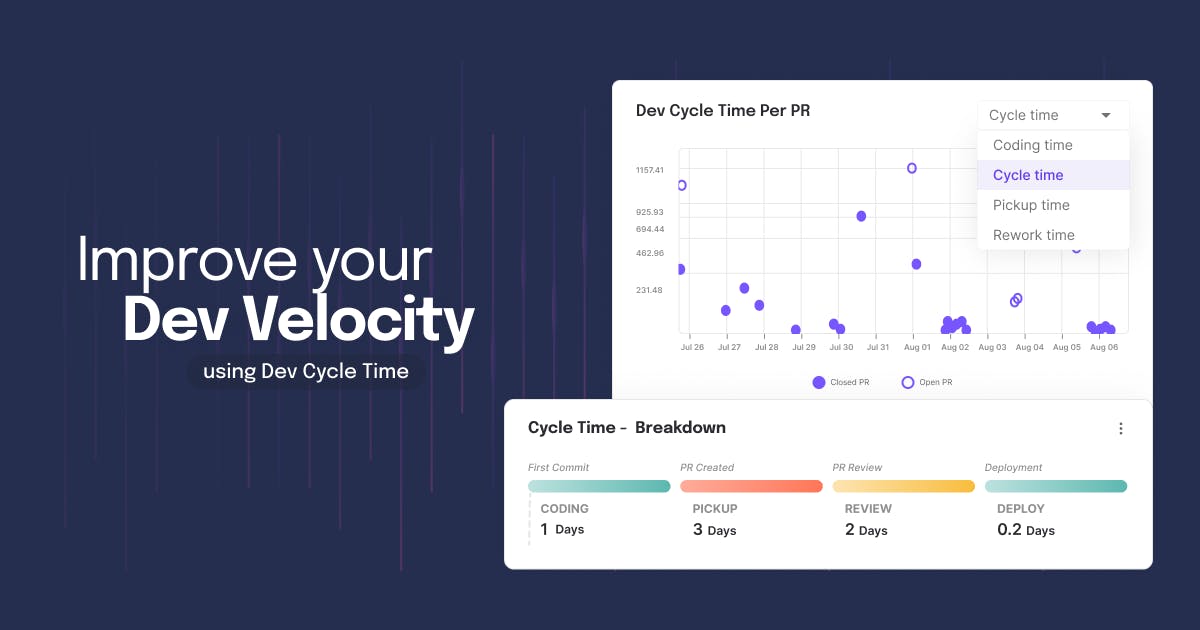
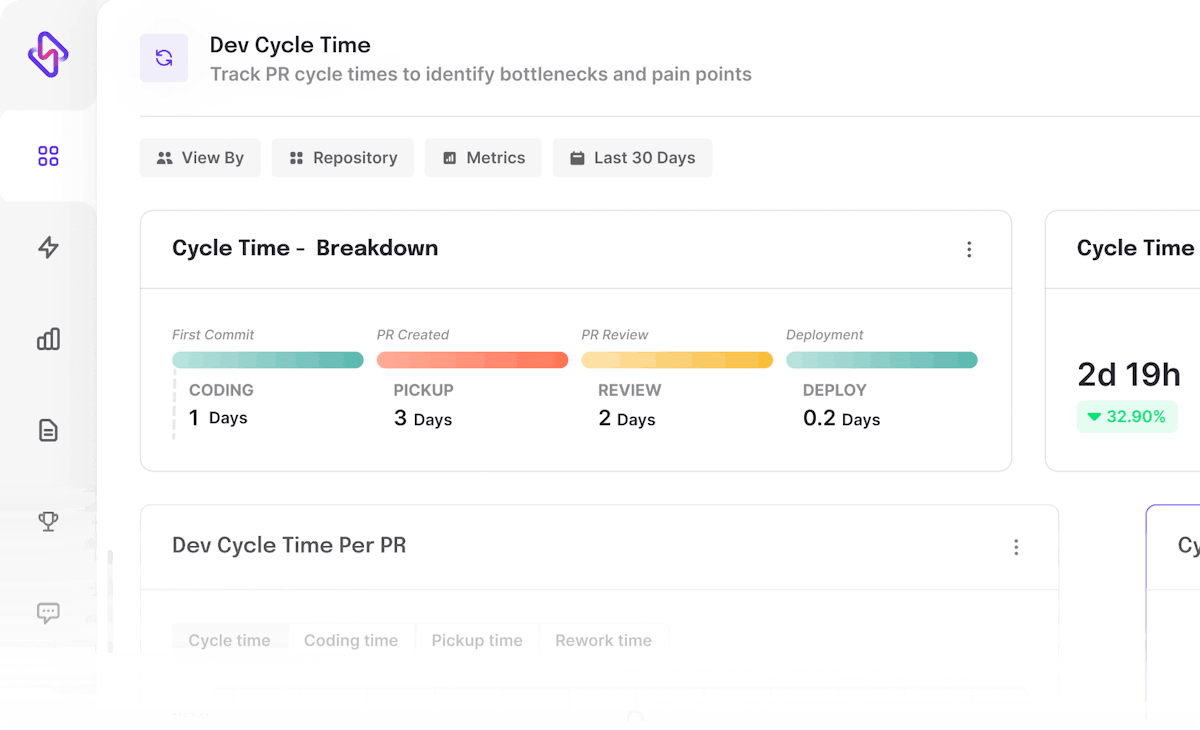
For most high-performing teams, Cycle time is less than 4 days. For these teams, the breakdown average ranges are:
The time to deploy remains specific and highly dependent on the kind of project or repository. Here, the average ranges for mobile are less frequent (from 1 to 4 weeks for consumer apps on average) while for active microservices they tend to be daily.
A trusted source for benchmarking time to deploy is the deployment frequency thresholds in DORA metrics as suggested by the Accelerate DORA actors themselves. More on this, here.