Imagine your team recovering from incidents swiftly, restoring services seamlessly, and minimizing the negative impact on customers and your bottom line. That's where Mean Time To Recovery (MTTR) comes into play.
DevOps has become a cornerstone of modern software development, with 83% of IT leaders relying on it to enhance their processes. Even minor performance improvements can have a significant impact on business outcomes. Today, integrating DevOps automation is a strategic decision. However, DevOps is not a silver bullet. To maximize its benefits, it's essential to implement it correctly and adhere to best practices.
While DevOps has shown positive trends in recent years, with a rise in high-performing teams, the 2022 State of DevOps report highlighted a concerning increase in low-performing teams. One of the most critical challenges for engineering managers is minimizing downtime during incidents. Every second counts.
There could be multiple things dragging down engineering teams. One such daunting challenge for engineering managers is to resolve incidents swiftly and minimize average downtime. Every second counts.
How would you feel if your engineering team could recover from incidents more rapidly? What if you could ensure smooth service restoration and minimize the impact on customers and the bottom line?
Well, that’s what Mean Time To Recovery (MTTR) can help you achieve.
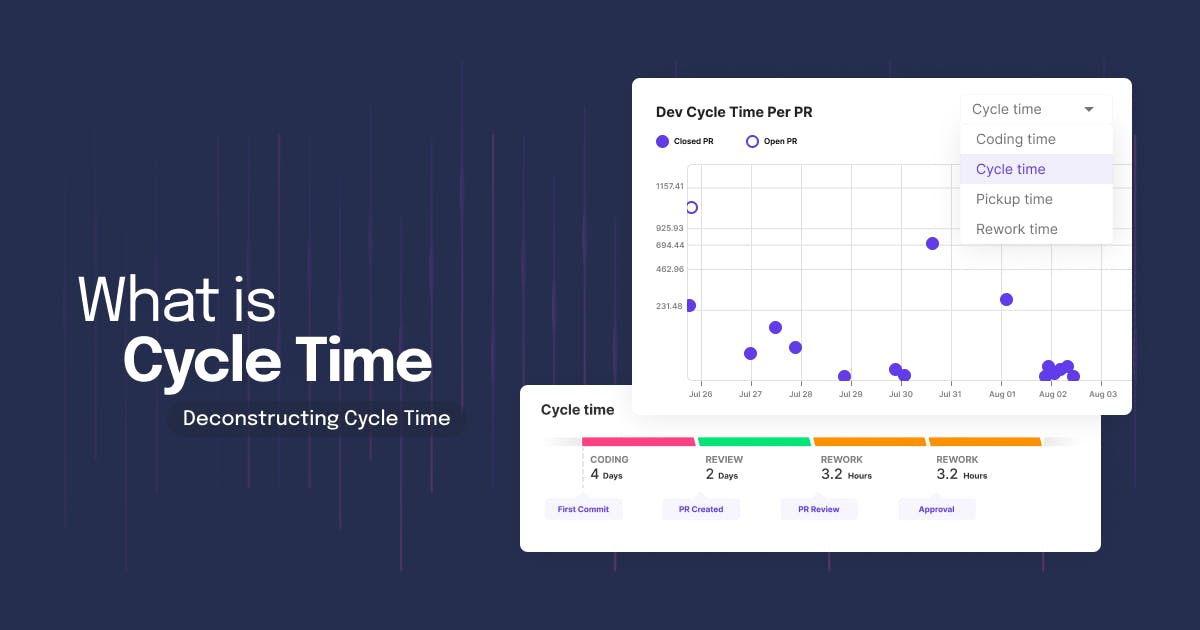
MTTR metrics are one of the crucial DORA Metrics that measure your team’s efficiency of incident response i.e., average time it takes to restore services.
Read this article to understand what’s MTTR, and to understand the significance of Mean time to recovery in alleviating the pain points of engineering managers. Also, you’ll discover actionable advice to significantly reduce MTTR.
What is the Mean Time To Recovery (MTTR)?
Let’s say you're working in stock trading, where every second counts. Suddenly, your trading application experiences a significant spike in latency. As a trader, you're relying on this application to execute time-sensitive transactions and capitalize on market opportunities. The latency issue not only hampers your ability to react swiftly to market conditions but could also lead to financial losses and a lot of frustration.
While we hope such situations never occur, they do highlight the critical nature of downtime, latency, and performance-related incidents in various sectors—whether it's finance, healthcare, retail, or even autonomous vehicles. As an engineering manager, you understand the weight of these incidents. Downtime leads to customer dissatisfaction, damages your brand’s reputation, and impacts the bottom line.
That’s where Mean Time To Recovery (MTTR) comes in. This metric helps you and your engineering teams focus on minimizing downtime and restoring systems to a fully functional state as quickly as possible. This not only ensures uninterrupted customer experiences but also helps retain their trust.
But what exactly is MTTR?
Mean Time To Recovery (MTTR) is a broad metric that measures the average time it takes to not just restore a service after an incident but also to bring it back to full operational capacity. This includes additional steps like verifying the system's health, completing all recovery processes, and ensuring that no further issues arise.
In short, MTTR is a key indicator of your engineering team's operational efficiency.
Let’s clarify the difference between Mean Time To Recovery and Mean Time To Restore. While Mean Time To Restore specifically measures the time taken to fix and restore the system to its normal operational state after an incident, Mean Time To Recovery goes a step further. It includes the entire recovery process, ensuring that the system is not only restored but also fully operational and stable, with no lingering issues.
Here’s a simple formula to calculate the Mean Time To Restore:
MTTR = Total Repair Time / Number of Incidents
For example, imagine your eCommerce application relies on a DynamoDB database to track the products a customer has viewed in the last hour. If the database experiences downtime, your machine learning algorithms won’t be able to fetch this data, leading to lost revenue and a less-than-ideal customer experience. Your engineering team must quickly investigate the root cause, diagnose the issue, and restore the database.
Suppose a junior developer unintentionally causes the downtime, and it takes 5 hours to fix the mistake. A similar incident happens again, and this time it takes 4 hours to reconfigure your cloud Identity & Access Management (IAM) system to prevent unauthorized access. The MTTR in this scenario would be:
MTTR = (5 hours + 4 hours) / 2 incidents = 4.5 hours
Reducing MTTR in this case is crucial to minimizing customer dissatisfaction, maintaining productivity, and protecting revenue.
By understanding and improving both Mean Time To Restore and Mean Time To Recovery, you can ensure your systems are not only fixed quickly but also fully operational and reliable, providing a seamless experience for your customers.
Mean Time to Restore Vs. Other MTTR Metrics
When we talk about MTTR, it’s easy to get lost in the sea of similar-sounding metrics. Let’s break down the differences so you can see how Mean Time to Recovery andother similar sounding words fit into the bigger picture.
1. Mean Time Between Failures (MTBF)
MTBF is a bit different. Instead of focusing on recovery, it looks at reliability. MTBF measures the average time between one failure and the next, giving you an idea of how long your system runs smoothly before something goes wrong. If your MTBF is high, it means your systems are pretty reliable.
Knowing your MTBF helps you understand how often you can expect issues to occur. It’s a valuable metric for planning maintenance and improving the overall durability of your systems.
2. Mean Time to Acknowledge (MTTA)
Mean Time to Acknowledge is the first step in the incident response process. It tracks how long it takes for your team to recognize that there’s a problem after being alerted. A quick acknowledgement is key to a swift recovery, as it sets the stage for everything that follows.
A fast MTTA shows that your alerting and monitoring systems are effective and that your team is ready to respond at a moment’s notice. If MTTA is slow, it could be a sign that your team needs better tools or more training.
3. Mean Time to Failure (MTTF)
MTTF measures the average time a system or component operates before it fails. It’s more predictive in nature, focusing on the lifespan of your systems rather than how quickly you can fix them. While it’s often used in hardware contexts, it can also apply to software and infrastructure.
MTTF is a good indicator of the longevity and reliability of your systems. By understanding MTTF, you can better predict when maintenance or replacements will be necessary, helping you avoid unexpected failures.
How To Calculate Mean Time to Recovery?
Calculating Mean Time to Recovery (MTTR) is a great way to understand how quickly your engineering team can get things back on track after something goes wrong. The formula is pretty simple, but the insights it gives you can make a big difference in how you manage and improve your systems.
The Simple Formula for MTTR
At its core, calculating MTTR comes down to this straightforward formula:
MTTR = Total Downtime / Number of Incidents
Let’s break that down:
- Total Downtime: This is the total amount of time your service or system was out of action. It includes not just the time spent fixing the problem but also any extra time needed to make sure everything is running smoothly again.
- Number of Incidents: This refers to the total number of issues or outages that occurred over a certain period.
An Easy-to-Follow Example
Let’s say your engineering team is responsible for a cloud-based service that had three different outages last month:
- The first outage took 2 hours to fix.
- The second one needed 4 hours to get sorted.
- The third, more complicated issue took 6 hours to fully recover.
To calculate Total Downtime, you’d add these up:
2 hours + 4 hours + 6 hours = 12 hours
You had 3 incidents in total, so your Number of Incidents is 3.
Now, plug those numbers into the formula:
MTTR = 12 hours / 3 incidents = 4 hours
So, on average, it took your team 4 hours to recover from each incident and get everything back to normal.
A lower MTTR is a good sign—it means your team is quick at fixing issues and getting things back on track, which is crucial for keeping customers happy and minimizing any negative impact on your business. If your MTTR is on the higher side, it might be worth looking into ways to improve your incident response processes, tools, or even the training your team gets.
Even though the formula is simple, a few things can affect your MTTR:
- Incident Complexity: Some issues are trickier than others and naturally take more time to resolve.
- Response Speed: How fast your team jumps on a problem once it’s detected can have a big impact on MTTR.
- Thorough Recovery: Sometimes, after the initial fix, you need extra time to make sure everything is really back to normal, which can add to your MTTR.
- Data Accuracy: The numbers you use in your MTTR calculation need to be spot-on. If your downtime or incident logs are incomplete, your MTTR won’t give you an accurate picture.
How Can You Improve Your MTTR?
To bring your MTTR down, focus on making your incident management process as smooth as possible. This could mean setting up better monitoring and alerting systems, improving team communication, or making sure everyone knows the best practices for handling incidents. Regularly checking your MTTR can help you spot areas where you can do better and make sure your team is always ready to tackle any problems that come up.
By keeping an eye on your MTTR and working to reduce it, you can build a more resilient system, minimize downtime, and keep your customers satisfied with a seamless experience.
Challenges of Measuring MTTR Accurately and Completely
While Mean Time to Recovery (MTTR) is a crucial metric for understanding how well your team handles incidents, measuring it accurately can be trickier than it seems. Several factors can make it challenging to get a true picture of your MTTR. Let’s dive into some of the common hurdles you might face.
1. Inconsistent Data Collection
One of the biggest challenges in measuring MTTR is ensuring that you have consistent and accurate data. If your team isn’t logging incidents properly or if there’s missing information, your MTTR calculations can end up being misleading. It’s like trying to measure your running speed with a stopwatch that only works half the time—it’s not going to give you the real picture.
Make sure your team is diligent about documenting every incident, including when it started, when it was resolved, and any steps taken in between. Consistent data collection is key to getting an accurate MTTR.
2. Variability in Incident Severity
Not all incidents are created equal. Some issues are minor and can be resolved quickly, while others are complex and take much longer to fix. This variability can skew your MTTR, making it seem like your team is either much faster or slower at resolving issues than they actually are.
To get a more accurate MTTR, consider categorizing incidents by severity and calculating MTTR separately for each category. This can help you better understand how your team handles different types of challenges.
3. Misalignment of Priorities
If your team isn’t clear on which incidents should be prioritized, you might find that critical issues take longer to resolve, which can negatively impact your MTTR. On the flip side, if your team is spending too much time on less important tasks, it can also inflate your MTTR.
Establish clear guidelines for prioritizing incidents based on their impact and urgency. This way, your team can focus on what matters most, and your MTTR will reflect your efficiency in tackling the most critical problems.
4. Recovery Verification Time
Another factor that can complicate MTTR measurement is the time it takes to fully verify that an incident has been resolved. In some cases, the initial fix might be quick, but ensuring that the system is stable and won’t encounter further issues can add extra time to your MTTR.
Include the necessary verification steps in your MTTR calculations, but be aware of how they might affect the overall number. It’s important to strike a balance between thoroughness and efficiency.
5. Human Factors
Let’s face it—humans aren’t perfect. Errors in judgment, miscommunication, and even fatigue can all play a role in how long it takes to resolve an incident. These human factors can introduce variability into your MTTR that’s hard to account for.
Foster a culture of continuous improvement and learning within your team. Regularly review incident responses to identify any areas where human factors might be affecting performance, and provide training or support as needed.
How to Reduce Mean Time To Restore?
Here are some simple steps to reduce your MTTR:
1. Streamline Incident Management Processes
Are your incident management protocols well-defined and effective?
- Implement a well-defined incident response framework to foster coordination and efficiency
- Leverage automation and orchestration tools to turbocharge incident reporting and resolution, and minimize human error.
2. Enhance Monitoring and Alerting Systems
Do you have a comprehensive incident monitoring & tracking system that acts as a sentinel for your critical systems?
- Configure intelligent alerting mechanisms to quickly inform concerned teams/ individuals.
- Make use of methods like anomaly detection and predictive analytics to detect and address issues before they snowball.
3. Inculcate a Culture of Collaboration and Knowledge Sharing
Is your team fully tapped into the power of collaboration?
- Encourage a culture of cross-functional teams, enabling faster incident resolution through shared expertise.
- Establish dedicated communication channels, such as incident response chat platforms, for immediate information exchange and collaboration.
- Cultivate incident post-mortems to document issues identified, lessons learned, and best practices, fueling continuous improvement.
Besides, you, as an engineering manager, can conduct regular incident retrospectives to reduce MTTR. These retrospectives and feedback loops help you and the team to identify underlying causes. You can proactively work on making your incident response team more productive and capable of addressing such issues. In the recovery process, ensure that incident post-mortems foster a culture of accountability and continuous learning, and not push the teammates into blame games, finger-pointing, or dirty organizational politics.
Also, to reduce MTTR, you can consider embracing automated remediation options provided by cloud vendors.
The Bottom line
Reducing MTTR can dramatically improve your DevOps team outcomes, help you build resilient engineering systems, and prevent issues from escalating into outages.
It may even reflect positively on your revenue reports, and save your customer success teams from burnout.
To attain operational excellence in the software supply chain, engineering managers can channel their focus toward streamlining incident management processes with automated monitoring systems, remediation tools, and an incident management tool, fostering a collaborative culture, and investing in the continuous improvement of the SDLC process. These together can help you prove your mettle in reducing MTTR.
To track MTTR, and 130+ engineering metrics & KPIs such as MTTD, Cycle time, velocity, and code churn, try Hatica — your goto engineering analytics platform to track all the critical engineering KPIs without any noise.
Gain a holistic view of your engineering health, and unleash your team's true potential.
FAQs
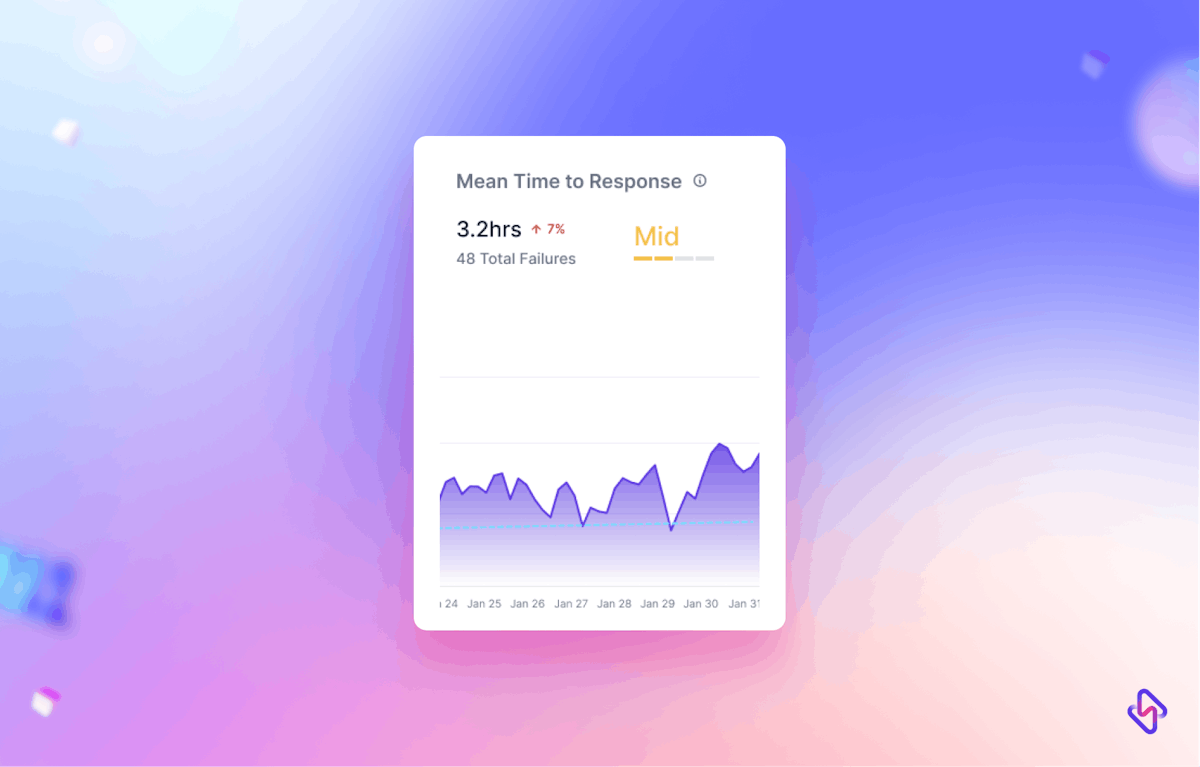
1. What really affects mean time to recovery?
MTTR can be influenced by a bunch of things. The complexity of the issue, how well your incident management processes are set up, the tools and technologies you have in place, and, most importantly, how ready and quick your team is to jump in and fix the problem—all of these play a role.
2. What is a good mean time to recovery?
A "good" MTTR varies by industry and the type of service you're offering. However, as a benchmark, high-performing teams often aim for an MTTR of under an hour. The key is to continuously strive to lower your MTTR over time.
3. When to use Mean Time to Respond?
Mean Time to Respond (MTTR) is best used when you need to see how quickly your team reacts after being alerted to an issue. It’s a great way to check if your monitoring systems are doing their job and if your team is ready to tackle problems as soon as they come up.