We’re seeing an increasing number of organizations renew their focus on adopting and improving their DevOps practices to help optimize their software development life cycle and improve their delivery velocity to reach markets and customers faster. Here’s all you need to know about the four key DevOps metrics and how teams can use these metrics to improve dev efficiency and performance to build better and faster products for their customers.
What are DevOps Metrics?
DevOps metrics are the data points used to measure the performance and efficiency of a team’s DevOps software development process. Since DevOps integrates the functions of both development and operation, the metrics should be able to measure and optimize the performance of both the processes and people involved.
Measuring and gathering insights from DevOps metrics can help managers gather actionable insights into their team’s processes and bottlenecks and take swift remedial actions in case of blockers. Thus, DevOps metrics enable teams in the successful completion of goals.
The Four Key DevOps Metrics:
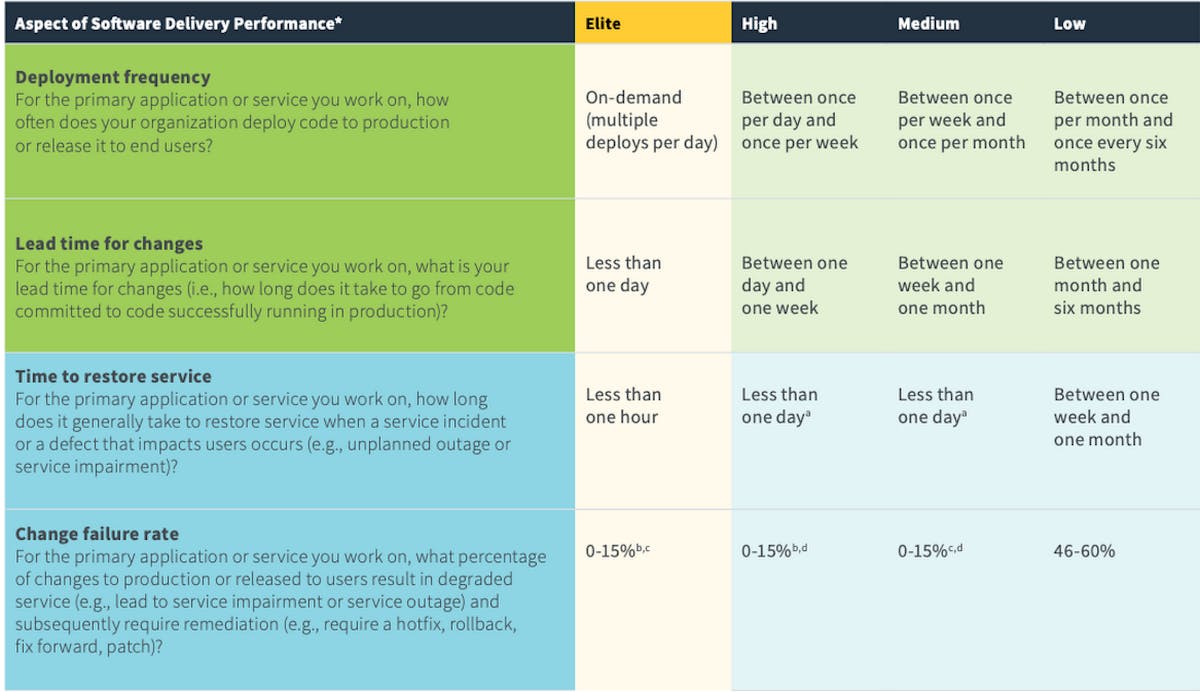
Google's DevOps Research and Assessment (DORA) team has identified four crucial metrics that can indicate and optimize the health of DevOps performance. The DORA Four Keys project aims at generating valuable data and gathering insights to amplify engineering productivity surrounding DevOps practices. Below are the four core DevOps metrics, known more commonly as DORA metrics:
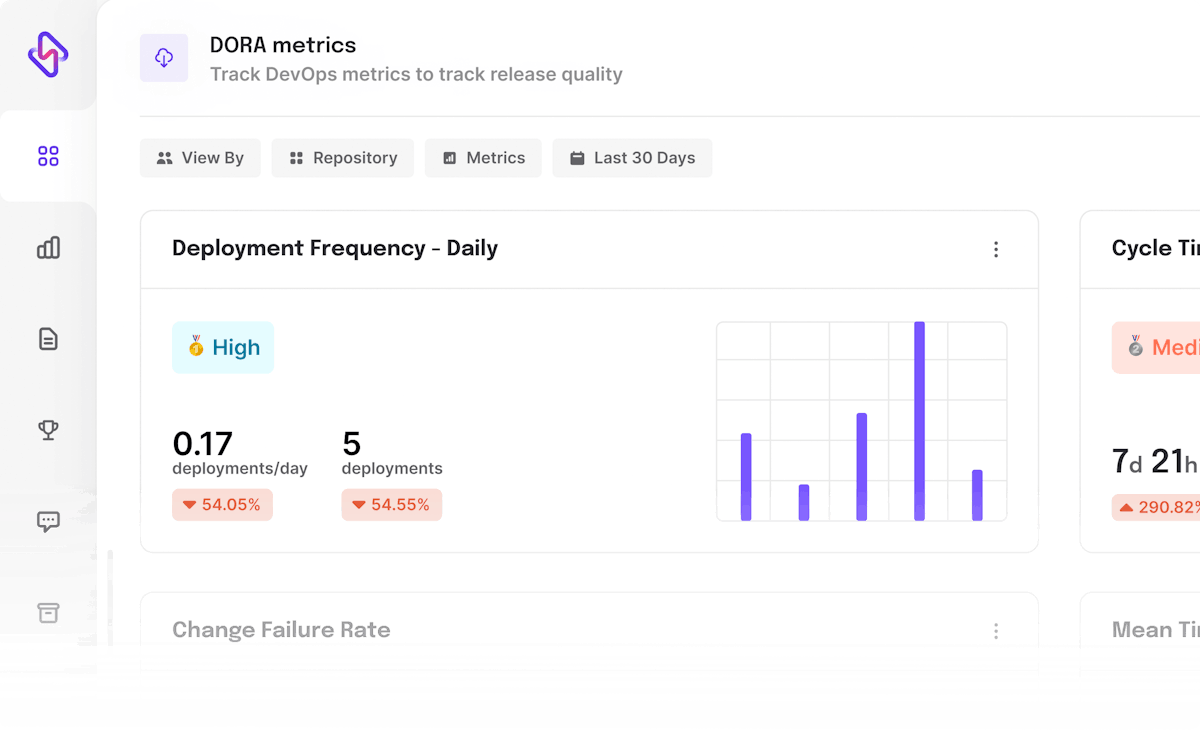
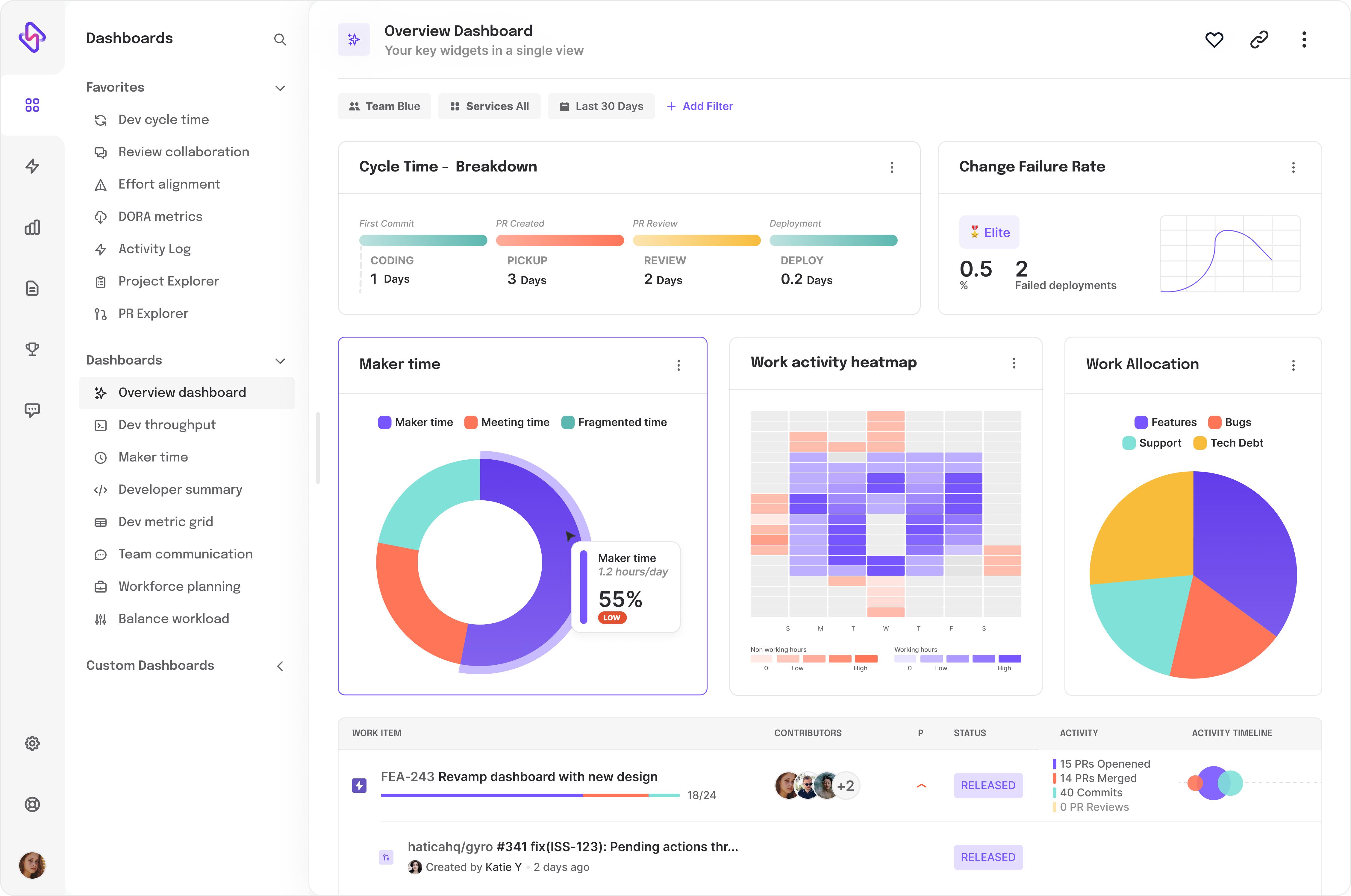
- Deployment Frequency - Measures how often a team successfully releases changes to production, indicating the speed with which the team delivers software
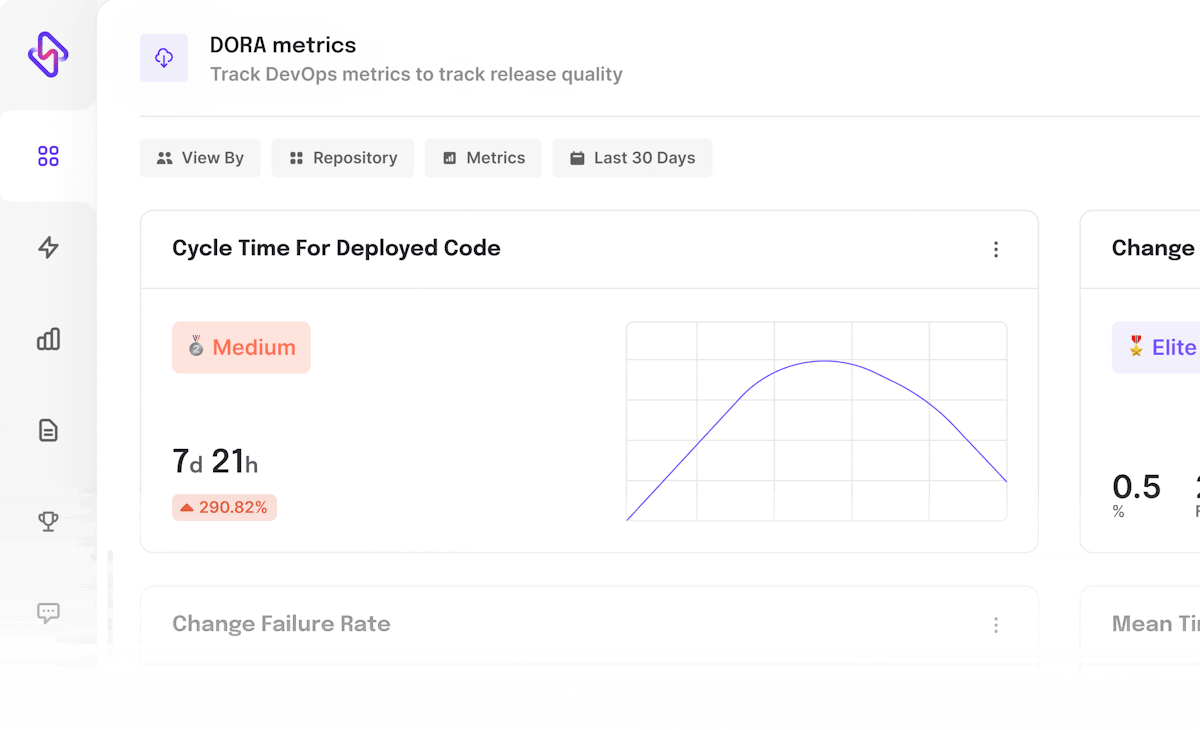
- Change Lead Time: The time from when the work on a change request begins to when it is put into production and consequently given to the customer is known as Change Lead Time. Teams use lead time to determine the efficiency of the development process
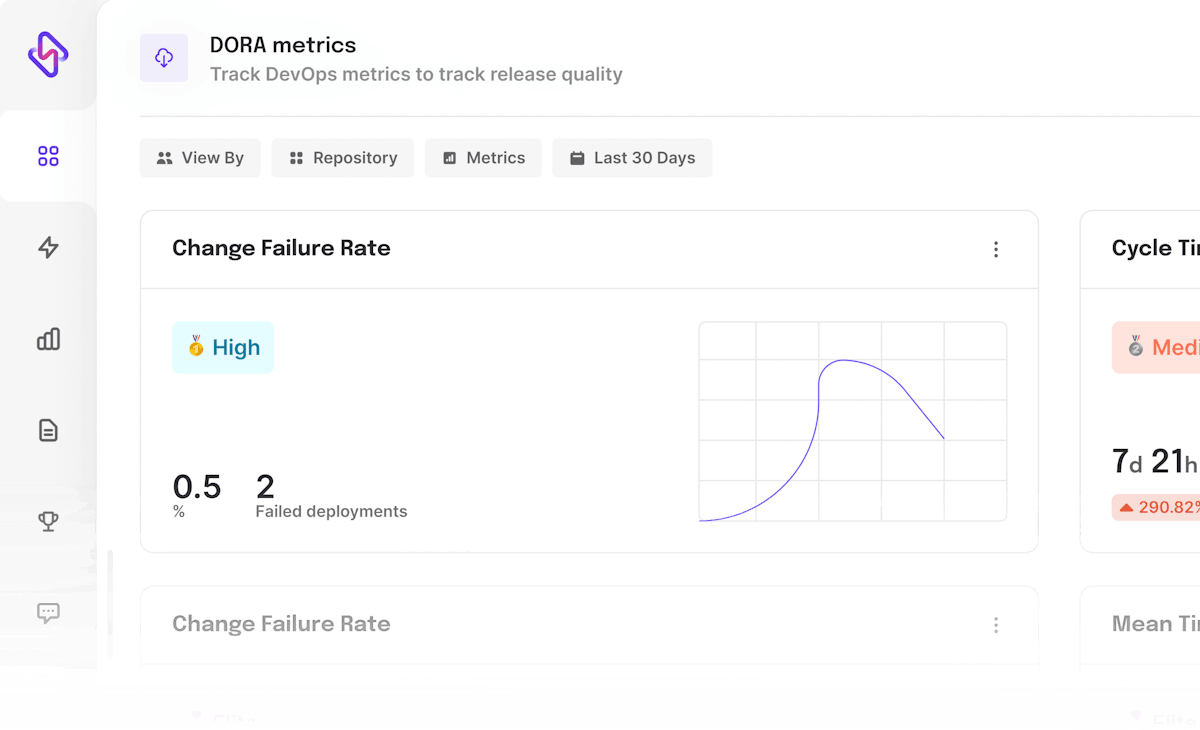
- Change Failure Rate: Measures the rate at which production changes cause a failure after release. It is an indicator of the quality of code produced by a team.
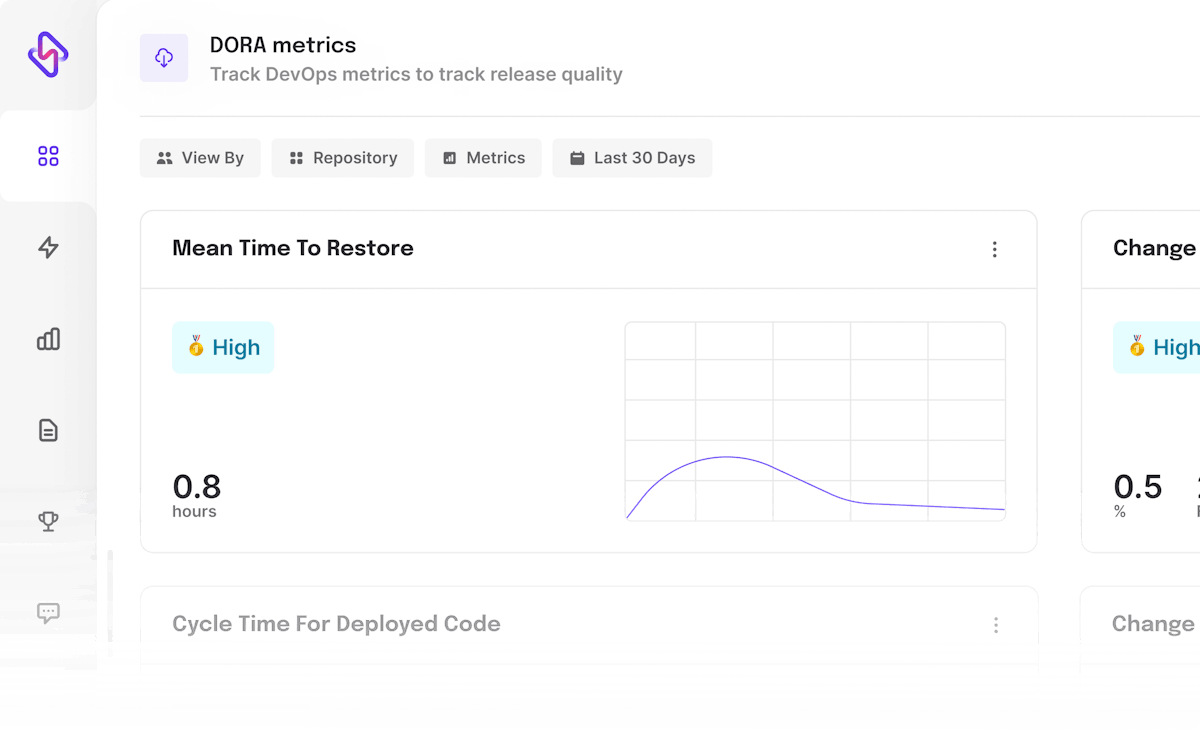
- Mean Time to Restore: Measures how long it takes for an incident or failure to be resolved through a production change.
While the measures of Deployment Frequency and Change Lead Time calculate the velocity of a team, the Change Failure Rate and Mean Time to Restore metrics focus on the stability of the software.
According to the 2019 Accelerate State of DevOps Report, this format of the DevOps metrics analyzes and categorizes teams into Low, Medium, High and Elite performers, with the latter being twice as likely to meet or exceed their organizational performance goals. By employing these indicators, organizations can track and improve the teams' performance and effectiveness of the processes.