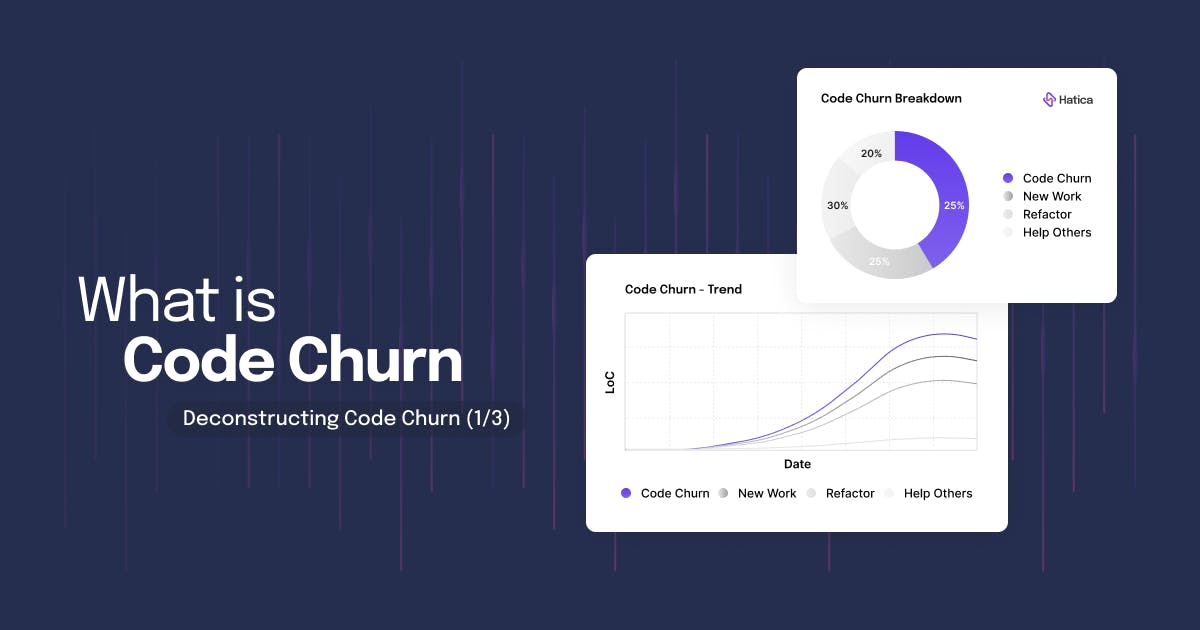
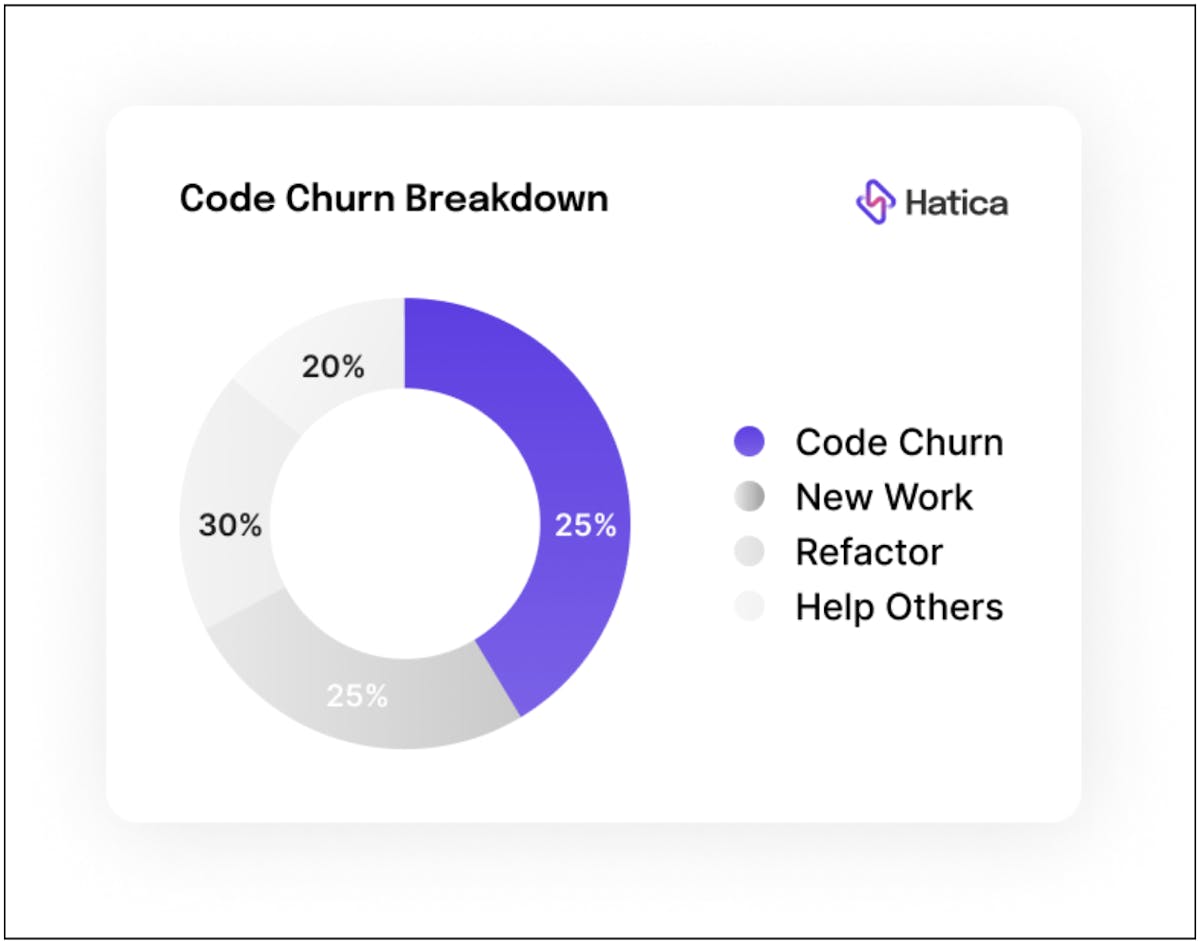
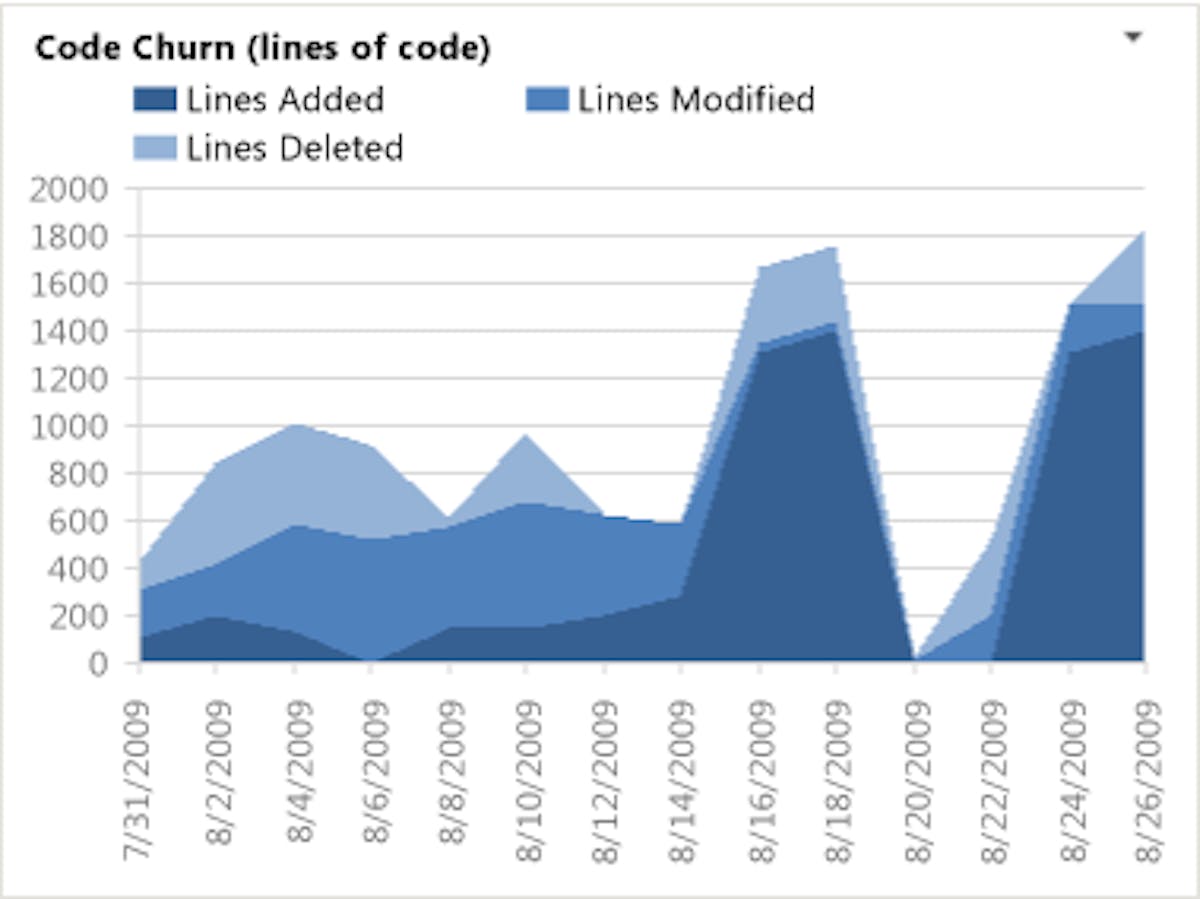
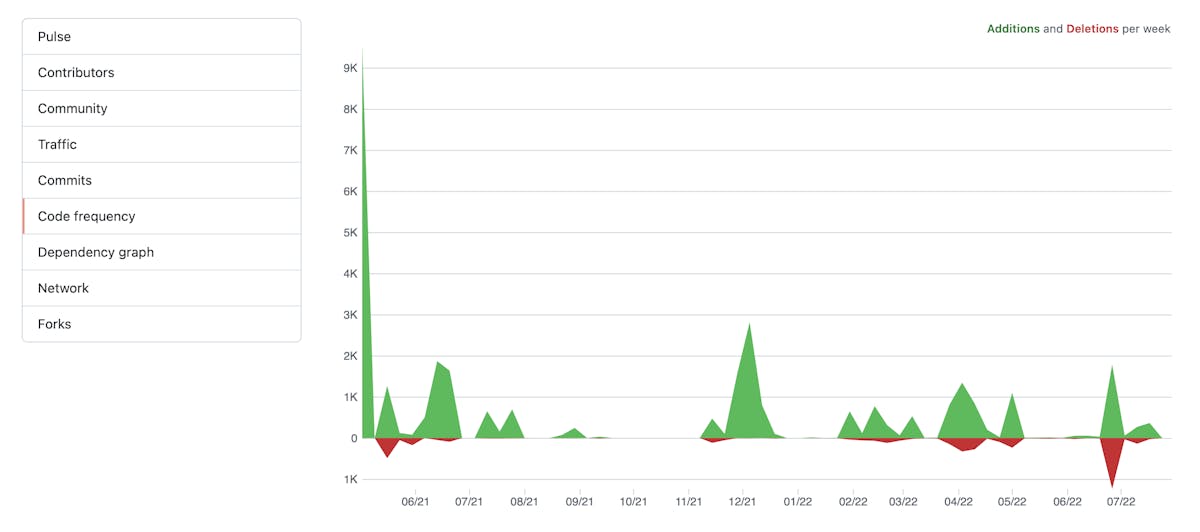
The Good Side of High Code Churn Rates
A higher code churn rate can be alarming at first glance. But, it does not always signal a problem. Understanding the root behind the staggering number can sometimes help decode the proactive reasons listed below.
1. Experimentation
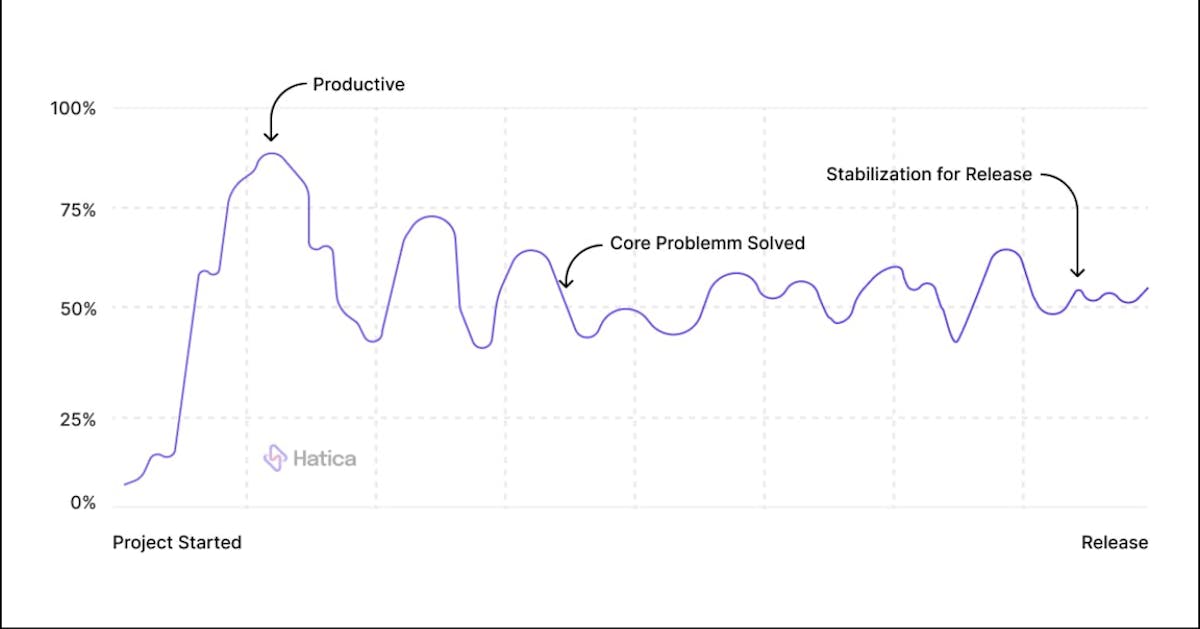
New modules sometimes demand a novel approach from the developer. During a time like this, the developer needs to work on a prototype code that can be different from earlier, resulting in higher code churn rates. This anomaly in the code churn is harmless or maybe productive. But, even a good reason like this can be problematic if it takes too much time right at the start of the development cycle and stretches the deadline beyond the allocated window. Hence managers should be vigilant while tracking code churn rates at different stages of the development cycle.
2. Optimization
Skilled developers can draw up the logic behind the feature or the module in a relatively shorter time. Sometimes they complete the code and even achieve the desired output. So they formulate a way to make the run-time shorter by coming up with improvements and changes. This could increase the rate of code churn, but this optimization-oriented approach signals proactivity and does not affect the development process. This again can backfire if the developer spends too much time optimizing a single feature jeopardizing the rest of the allocated module or features.
3. Collaboration
Developers tend to help their colleagues whenever they feel stuck. During this collaboration, the new developer who has come on board could suggest big and small changes that could result in multiple revisions to the existing code. The new changes can result in higher code change numbers that don’t signal an alarm. Even this new code churn rate should be monitored and ensured that only the necessary changes are made rather than committing to changing the entire blocks of code. This can result in resource leakage.
The Bad Side Of High Code Churn Rates
Higher code churn that spells disaster can be nullified if managers track the churn trend from the beginning of the project. Organizations can further classify the reason for a higher code churn rate into internal and external.
Internal
- Overachievement: Organizations tend to focus on building the MVP version faster to get an idea of staying ahead. Sometimes, the fast-paced method can cause an overlook of the core functionalities or requirements which can result in higher churn rates in the future.
- Perfectionism: Developers tend to rework the same blocks, only to make them perfect. This excessive attention to detail with no returns on the functionality can negatively impact the deadlines.
- Employee Burnout: Having high churn rates in the same areas of the codebase for an extended period can mean the developer is stuck. Not paying heed to the situation can cause the developer to develop boredom, a sense of not being competent, and ultimately, burnout. Managers can identify this by tracking code churn at regular intervals and taking corrective measures. Here's how organizations can weed out software engineer burnout.
External
- Tough feature: Sometimes, the clients can demand features or modules that are difficult to implement in a shorter period. Unprecedented requirements cause a spike in the code churn rates.
- Added changes after release: External stakeholders may slip in new change requirements not mentioned in the Product Requirements Document during stand-ups or reviews. This can cause unnecessary reworks and code churns.
- Unclear requirements: Miscommunication among the team and the clients can cause chaos sprint after sprint, causing a chink in the armor of an optimal churn rate. Requirements should be made clear at the beginning of the development cycle and verified after every update.
Factors Contributing To Unproductive Code Churn
1. Complicated Tasks
A higher level of churn is to be expected when an engineer is exploring and backtracking with a particularly challenging problem at hand. It is when the exploration has gone on for too long that it is a call for concern.
An unusual high churn level might indicate that an engineer did not completely understand the assignment, or neglected to fully comprehend the issue, or didn’t have the expertise to address the assignment. In many cases, engineers feel that they have successfully handled the issue, perhaps even sending it off for code review, and then finding that significant areas of it needed to be changed.
2. Unclear Requirements or Changing Requests From External Stakeholders
Factors outside the normal development process such as a poor PRD (product requirements document) or unclear or indecisive stakeholders can also lead to high code churn. A sudden increase in churn or a sudden spike in new work, especially in the final phases of a project, is usually an indication that a miscommunication between the stakeholders or new requirements led to the final code undergoing changes. When this pattern is seen sprint over sprint with the same team it can damage both morale and progress and can lead to frustration in the team over time.
3. An Indicator of Future Quality Problems
Measuring code churn equips managers with foresight to predict and preempt potential future problems. The most problematic code is the one that is complicated to grasp and altered frequently. A high level of churn exposes potential code hotspots, and if these frequent changes are performed on complicated and critical code, the code tends to be more error-prone. Hence, code churn can be a predictor of high-risk code.
These code hotspots, if not recognized early during refactoring efforts, can result in developers accumulating huge amounts of technical debt. This debt grows as more opportunities for code refactoring are missed and, as a result, new development becomes difficult, especially when features are built upon legacy code.
4. Deadline is at Risk
A higher percentage of reworking and code deletion resulting from experimentation is commonly seen at the beginning of a project — especially when a project is new or unfamiliar. A similar trend, sometimes called “exploratory churn”, is expected in the case of particularly challenging problems. Although code churn resulting from creative problem-solving is a positive outcome, it becomes a risk to meeting project deadlines when such experimental coding continues for a long period of time, risking the timeline of the development cycle.
Similarly, churn should stabilize as a project nears the release timeline. An early indication that the delivery ought to be pushed back is when you start seeing a high volume of churn leading up to a release.