DevOps is ubiquitous. 83% of IT decision-makers are banking on it to improve their software engineering processes. And why not?
The slightest of performance improvements can have an awesome influence on your business KPIs.
Besides, we are living in a cut-throat competitive market, where your competitors are vigilant and watchful to tear you apart, even with Threads (sorry Twitter). So, it’s intelligent to stitch DevOps-powered automation into your SDLC processes.
But DevOps is no panacea or placebo.It’s no panacea as you still need to do it right and follow DevOps best practices to squeeze value out of it.
It is not a fad either, as the State of DevOps reports a significant rise in high-performance DevOps practicing engineering teams between 2018-2021.
The report also highlighted a significant rise in low-performers in 2022.
There could be multiple things dragging down engineering teams. One such daunting challenge for engineering managers is to resolve incidents swiftly and minimize average downtime. Every second counts.
How would you feel if your engineering team could recover from incidents more rapidly? What if you could ensure smooth service restoration and minimize the impact on customers and the bottom line?
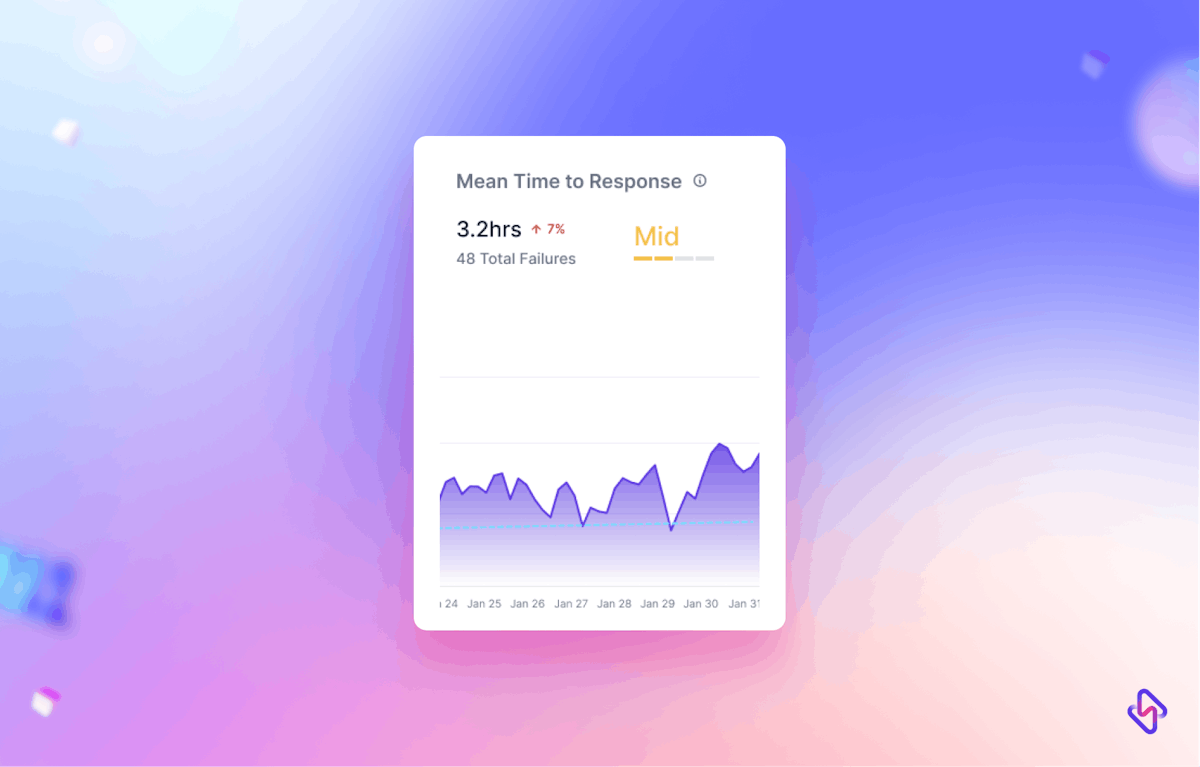
Well, that’s what Mean Time To Recovery (MTTR) can help you achieve.
MTTR is one of the crucial DORA Metrics that measure your team’s efficiency of incident response i.e., average time it takes to restore services.
Read this article to understand what’s MTTR, and to understand the significance of Mean time to recovery in alleviating the pain points of engineering managers. Also, you’ll discover actionable advice to significantly reduce MTTR.
What’s MTTR?
If you’re acquainted with the world of stock trading, imagine a situation where your trading application experiences a sudden and significant spike in latency.
Aren’t you, as a trader, heavily relying on this application to execute your time-sensitive transactions to capitalize on market opportunities?
Wouldn’t the latency issue hamper your ability to swiftly react to market conditions? In fact, it may potentially lead to financial losses. Not to mention all the frustration & trouble that follows.
Well, we pray nothing as such happen to anyone.
But that’s just one scary situation. Software downtime, latency, and performance-related incidents can be terrible for healthcare, retail, autonomous cars, finance, and even for public governance.
As an engineering manager, you bear the weight of downtime, customer dissatisfaction, and plummeting brand reputation.
So, it becomes imperative for you and the respective engineering teams to expedite the incident resolution mechanism, minimize the Mean Time To Recovery (MTTR), and restore systems back to a fully functional state.
This helps in delivering uninterrupted customer experiences and retains their trust as well.
But what’s MTTR?
MTTR is an acronym for Mean Time To Recovery. It’s a metric that quantifies your team's ability to swiftly respond to incidents, revive operations, and ensure business continuity. The quicker you can resolve incidents, the faster you can restore normalcy and safeguard your own and your customer’s interests.
In short, MTTR measures the pulse of your engineering team's operational efficiency.
Here’s a simple formula to calculate MTTR:
MTTR = (Total Repair Time / Net Failure Incidents)
So, let’s say, a DynamoDB database that your eCommerce application uses to track the list of products a customer has viewed in the last hour is experiencing a downtime. Now, your ML algorithms fail to fetch & feed on this data to recommend personalized products. This results in revenue loss, and not so delightful customer experience compared to other platforms. Thus, the engineering team must promptly investigate the root cause behind the database being unavailable, diagnose issues, and take corrective actions to restore the database.
Let’s say, you found out that this was because of the mishap a junior developer did, while s/he was not supposed to even work on it. Anyway, it took you 5 hours to fix the mistake. But again this happens next time. You realize, that you need stronger cloud access management to minimize incidents emerging due to unauthorized access from internal talent. So, you reconfigure your cloud Identity & Access Management system (IAM). Let’s say, this took 4 hours.
Your MTTR here is (5 hours + 4 hours)/2 => 4.5 hours.
Reducing the MTTR in this case is crucial to minimize customer dissatisfaction, and maintain productivity & revenue.
How to reduce MTTR?
Here are some simple steps to reduce your MTTR:
1. Streamline Incident Management Processes
Are your incident management protocols well-defined and effective?
- Implement a well-defined incident response framework to foster coordination and efficiency
- Leverage automation and orchestration tools to turbocharge incident reporting and resolution, and minimize human error.
2. Enhance Monitoring and Alerting Systems
Do you have a comprehensive incident monitoring & tracking system that acts as a sentinel for your critical systems?
- Configure intelligent alerting mechanisms to quickly inform concerned teams/individuals.
- Make use of methods like anomaly detection and predictive analytics to detect and address issues before they snowball.
3. Inculcate a Culture of Collaboration, and Knowledge Sharing
Is your team fully tapped into the power of collaboration?
- Encourage a culture of cross-functional teams, enabling faster incident resolution through shared expertise.
- Establish dedicated communication channels, such as incident response chat platforms, for immediate information exchange and collaboration.
- Cultivate incident post-mortems to document issues identified, lessons learned, and best practices, fueling continuous improvement.
Besides, you, as an engineering manager, can conduct regular incident retrospectives to reduce MTTR. These retrospectives and feedback loops help you and the team to identify underlying causes. You can proactively work on making your incident response team more productive and capable to address such issues. In the process, ensure that incident post-mortems foster a culture of accountability and continuous learning, and not push the teammates into blame games, finger-pointing, or dirty organizational politics.
Also, to reduce MTTR, you can consider embracing automated remediation options provided by cloud vendors.
The Bottom line
Reducing MTTR can dramatically improve your DevOps outcomes, help you build resilient engineering systems, and prevent issues from escalating into outages.
It may even reflect positively on your revenue reports, and save your customer success teams from burnout.
To attain operational excellence in the software supply chain, engineering managers can channel their focus toward streamlining incident management processes with automated monitoring systems, remediation tools, and an incident management tool, fostering a collaborative culture, and investing in the continuous improvement of the SDLC process. These together can help you prove your mettle in reducing MTTR.
To track MTTR, and 130+ engineering metrics & KPIs such as MTTD, Cycle time, velocity, and code churn, try Hatica — your goto engineering analytics platform to track all the critical engineering KPIs without any noise.
Gain a holistic view of your engineering health, and unleash your team's true potential.